
FastText是Facebook于16年提出的一个轻量级的模型,Fasttext最大的特点是模型简单,只有一层的隐层以及输出层,因此训练速度非常快,在普通的CPU上可以实现分钟级别的训练。同时在多个标准的测试数据集上,Fasttext在文本分类的准确率上,和一些深度学习的方法接近。
一, 原理
1, 模型结构
FastText的网络结构与word2vec中的CBOW很相似,主要包含一个投影层和一个输出层,如下图所示。
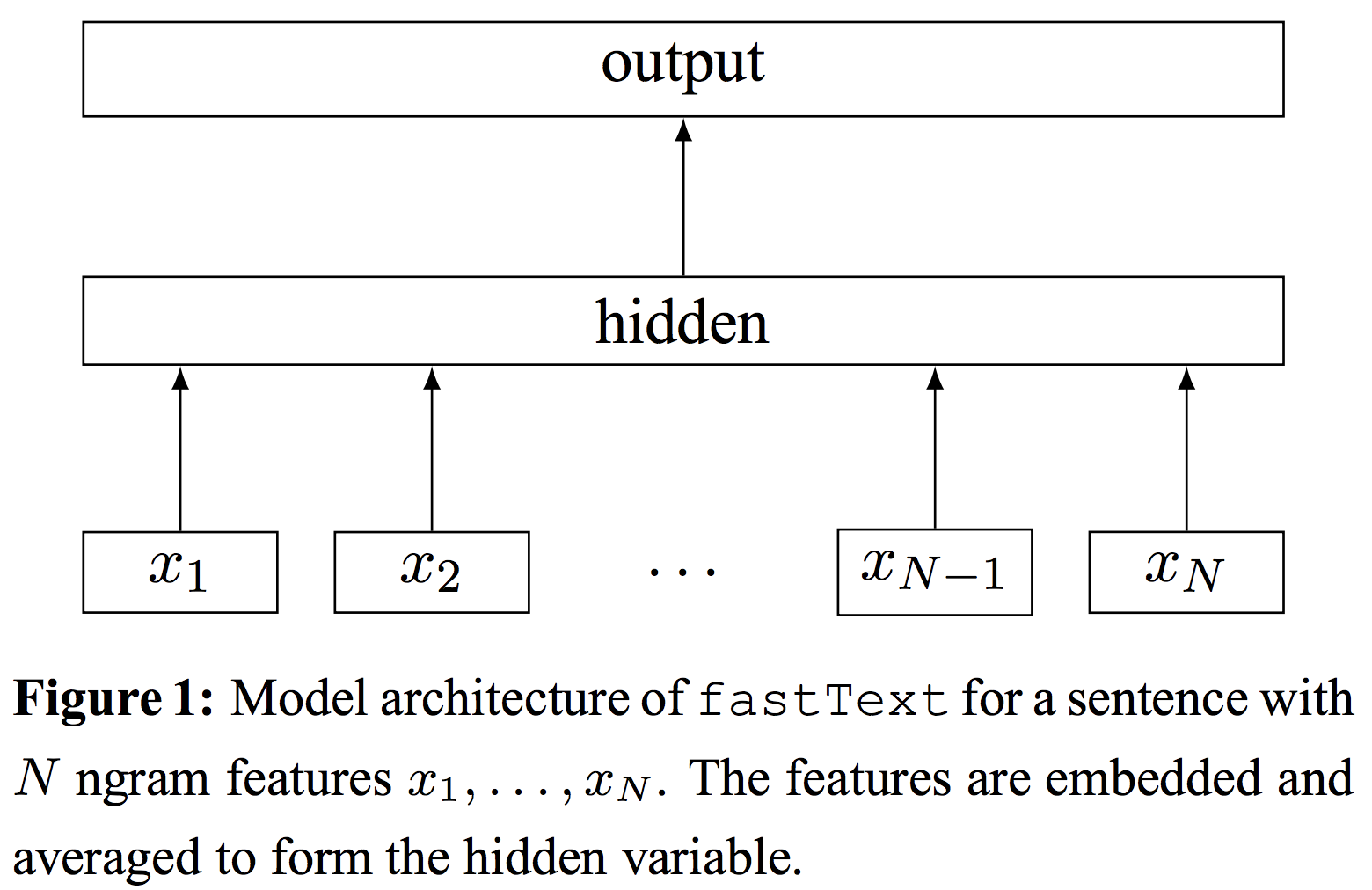
对于一个有N个文本的集合,损失函数为交叉熵损失,及负对数极大似然函数。
\[-\frac{1}{N}\sum_{n=1}^Ny_n\log(f(BAx_n))\] 其中 \(x_n\) 为第 \(n\) 个文本归一化之后的词袋特征,\(y_n\) 是类别,\(A\) 为隐藏层(投影层)的权重矩阵(a look-up table over the words),\(B\) 为输出层的权重矩阵。每个特征会首先根据 id 映射到 \(A\) 中对应的向量,然后,对计算 \(n\) 个特征向量的平均作为整个文本的向量表示,最后,将文本向量经过输出层,采用 \(softmax\) 函数 \(f\) 计算得到该文本在每个类别对应的概率表示。
\[w_i = Ax_i \\ h_{doc} = \frac{1}{n}\sum_{i=1}^nw_i \\ z = sigmoid(Bh_{doc})\]2, 层次softmax
标准softmax的复杂度为 \(O(kh), k\) 为总类别数,\(h\) 为文本向量的维度。当类别数很大时,模型的计算会耗费大量的时间和资源。为了提高速度,FastText将输出层的softmax改为基于哈夫曼树的层次softmax,计算时间复杂度可以缩减为 \(O(h\log_2k)\)。层次softmax会根据各个类别出现的频率进行排序,如下图所示,
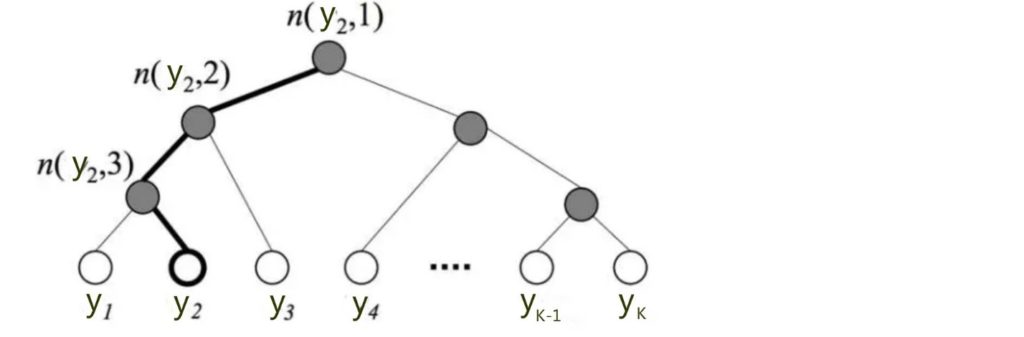
其中,每个叶节点表示一个类别,当叶节点的深度越深时,其概率将越低,假设一个叶节点的深度为 \(l+1\),其父节点列表为 \(n _ { 1 } , \ldots , n _ { l }\),则该叶节点的概率计算公式为:
\[P \left( n _ { l + 1 } \right) = \prod _ { i = 1 } ^ { l } P \left( n _ { i } \right)\]3, N-gram
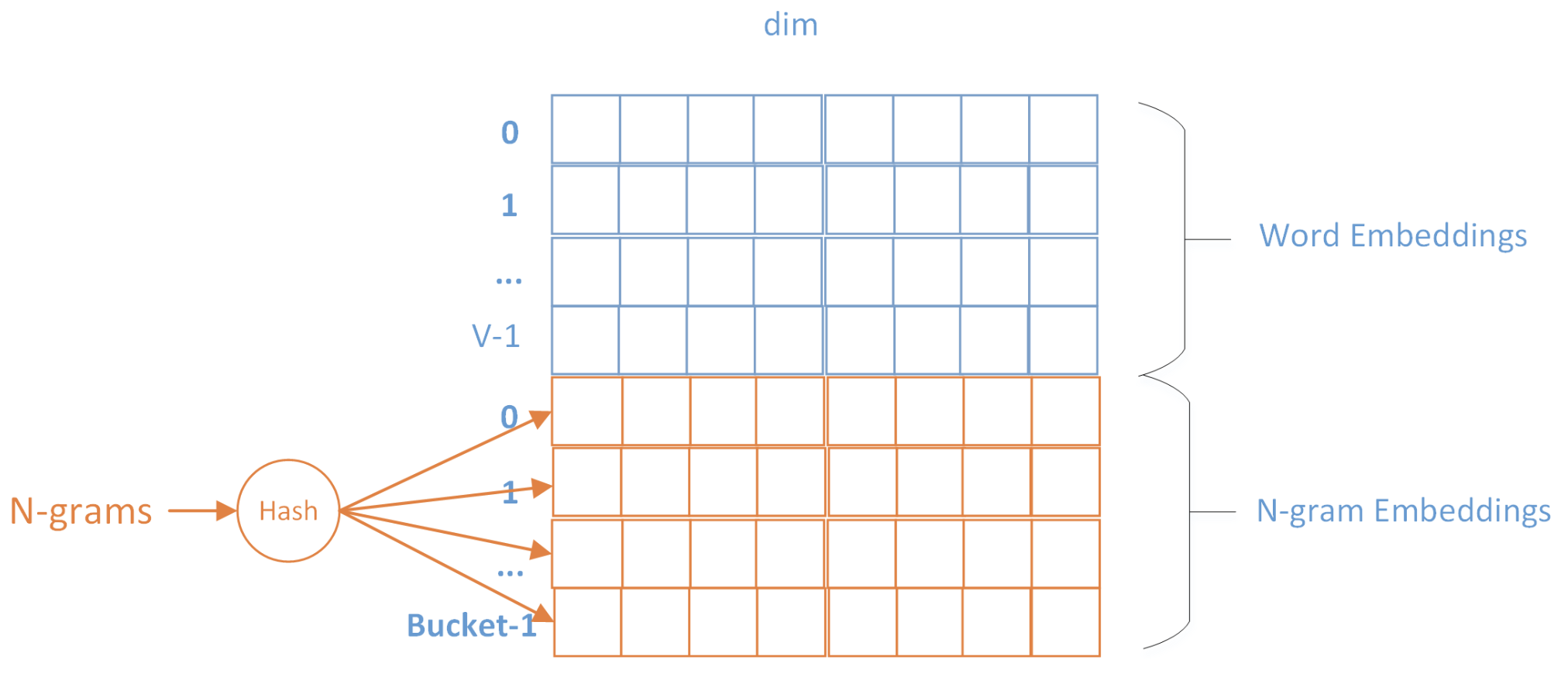
由于隐层是通过简单的平均得到的,丢失了词顺序的信息,为了弥补这个不足,Fasttext增加了N-gram的特征。假设某篇文章只有3个词,\(w_1, w_2, w_3\),N-gram的N取2,则输入为 \(w_1, w_2, w_3\) 和 \(bigram: w_1w_2,w_2w_3\) 的embedding向量,文章的隐层可表示为:
\[h=\frac{1}{5}(w_1+w_2+w_3+w_{12}+w_{23})\] 具体实现上,由于N-gram的量远比word大的多,完全存下所有的n-gram也不现实。由于N-gram表示的稀疏性(特别是对于短文本),Fasttext采用了Hash trick的方式,对n-gram进行哈希操作,哈希到同一个桶的所有N-gram共享一个embedding vector。如下图所示:
4, FastText和Word2Vec的异同
fastText和word2vec的CBOW模型结构非常相似,都包含一个隐层和一个输出层,softmax都是用基于哈夫曼树的层次softmax;
不同处:
- CBOW的目的是在输入层得到词向量,fastText的目的则是得到文本的分类标签。
- CBOW使用窗口内的上下文预测中心词,因此得到的词向量可以表达词之间的相对位置,可以用于别的NLP任务;FastText使用一整个文本的词及N-gram预测文本标签,虽然输入层也可以产出词向量,更多包含的则是该词对类别标签的贡献信息,很少迁移到别的任务(个人理解)。
二, 实践
FaceBook FastText 工具的使用:https://github.com/facebookresearch/fastText