
本文结构为:
- 为什么提出Albert
- Albert的主要贡献及创新点
- Factorized Embedding Parameterization
- Cross-layer parameter sharing
- Inter-sentence coherence loss
- Albert源码解读(无官方代码,github最高赞代码在Bert代码基础上做修改,结构基本一样,详情见Bert原理及源码解读,不作更多解释)
- keras下使用Albert(和Bert类似,不详细解释,Keras下微调Bert以实现文本分类)
- Bert、Roberta、Ernie、Albert模型对比
一,为什么提出 Albert ?
Albert 即为 A Lite Bert,一个轻量级的 BERT 模型,为ICLR 2020 收到的一篇投稿,出自谷歌。
目前在NLP中比较领先的模型通常都有数亿甚至十几亿的参数,Bert有1.1亿参数,Bert_large有3.34亿参数。在预训练自然语言模型时,增加模型大小和参数量通常能够提升下游任务的效果(larger hidden size, more hidden layers, and more attention heads),但模型复杂到一定程度之后,由于GPU / TPU内存限制和训练时间因素,增加模型大小会变得更加困难,并且有可能会导致”model degradation”现象,即效果变差。
Albert的论文中做了相应的实验,在Bert中增加hidden size的大小,反而导致效果变差。

二,Albert的主要贡献及创新点
基于上面的问题,Albert提出了三种优化策略,做到了比Bert小很多的模型,训练速度更快,但效果反而超越了Bert和XLNet。
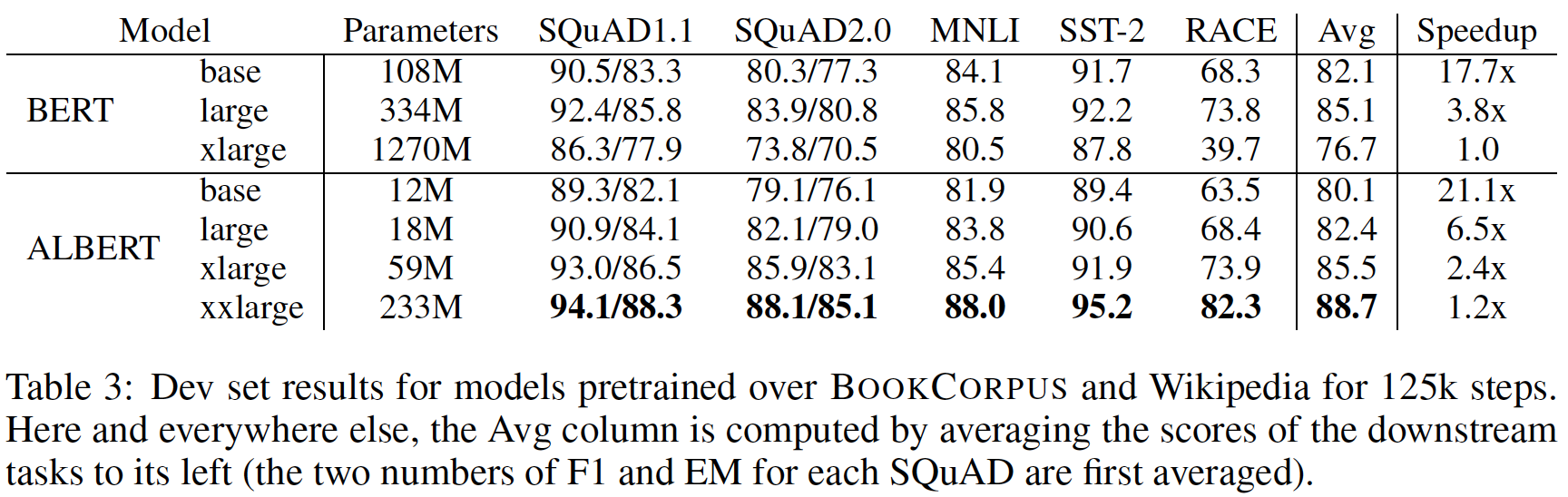
Albert和Bert在参数量、下游任务效果及训练时常上的对比:
Factorized Embedding Parameterization
在Bert和XLNet中,词表的embedding size (E) 和transformer层的hidden size (H)是相同的,但vocabulary的大小一般都很大,增大hidden size就会导致模型参数量变得很大。从模型的角度来看,WordPiece embeddings旨在学习与上下文无关的表示,而hidden-layer embeddings是为了学习上下文相关的表示。
Albert训练一个独立于上下文的embedding(VxE),之后计算时再投影到隐层的空间得到一些长度为hidden size的表征,相当于做了一个因式分解,分解大的vocabulary embedding matrix成两个较小的矩阵(O(V*H) –> O(V*E + E*H))。以ALBert_large为例,V=30000,H=1024,E=128,那么原先参数为 V*H= 30000*1024 = 30.73M 个参数,现在则为 V*E + E*H = 30000*128+128*1024 = 3.91M。
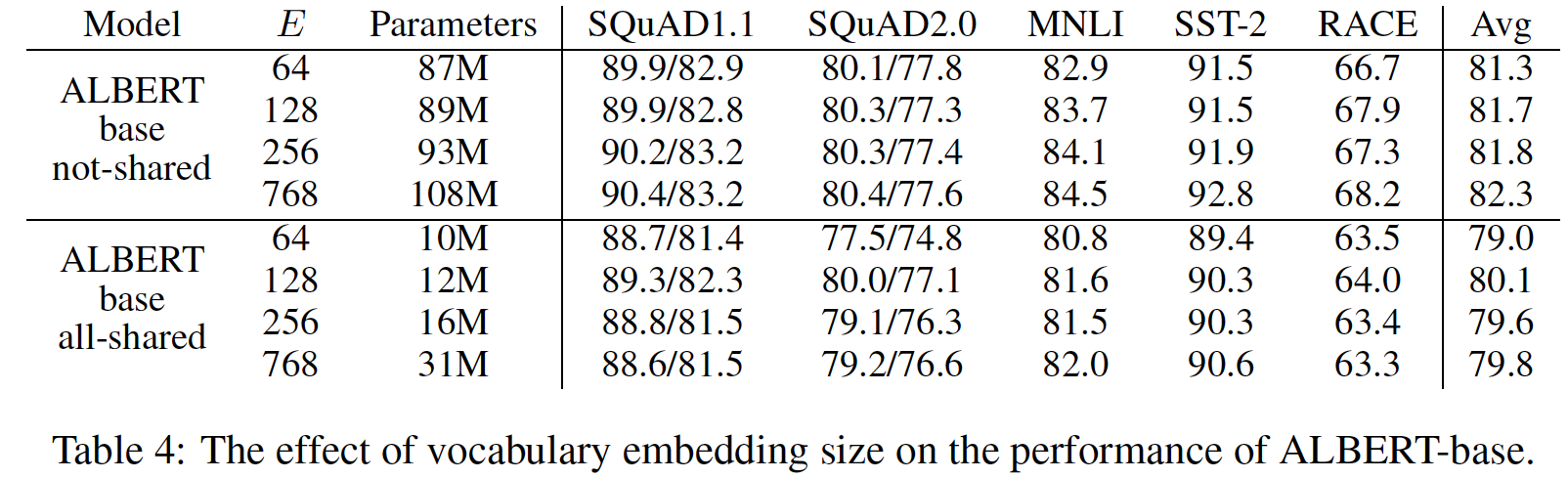
论文对比了all-shared和not-shared两种Albert下,E的变化对于下游任务效果的影响,对于all-shared Albert,E=128的效果优于E=H=768;对于not-shared模型调整E之后的效果会略低于E=H=768的情况。(没关系,底下会说明并不会使用not-shared Albert,shared-attention > all-shared > not-shared)
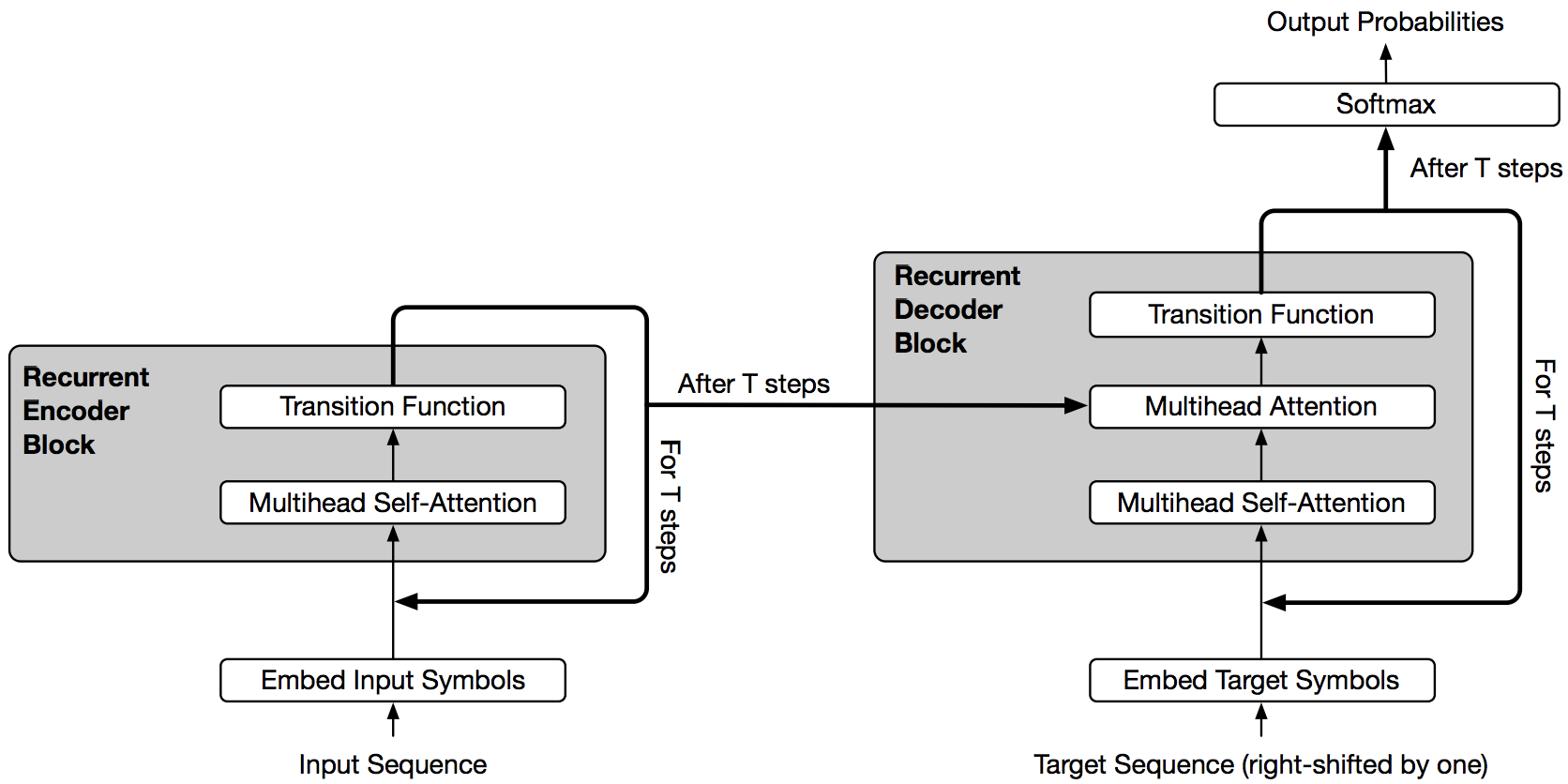
Cross-layer parameter sharing
Albert中使用跨层参数共享,即Universal Transformer的思想,如下图。与主观认知不同,在一些任务中,这种跨层参数共享的网络结构的表现反而比标准的transformer表现更好。
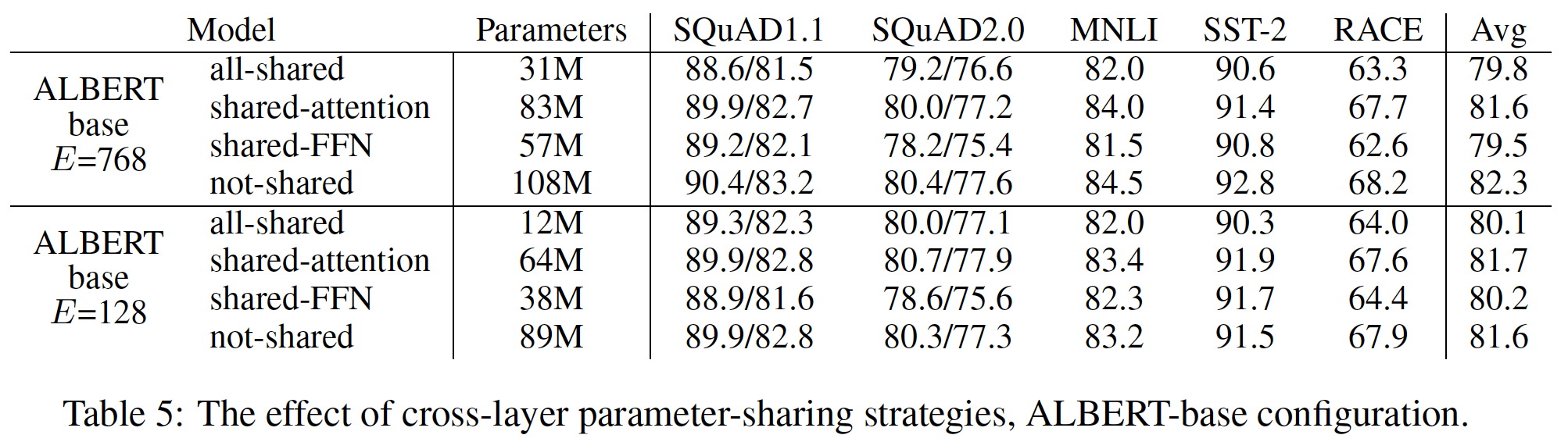
参数共享的方式有仅共享全联接层的参数,仅共享attention的参数,或者全部参数共享。论文中对这几种参数共享做了实验对比,结果如下图,全部参数共享参数量显著下降,但在所有情况下的效果都变差,在E=128的情况下对于模型效果的影响程度较小;仅共享全联接层的参数也是在所有情况下的效果都变差;仅共享attention的参数在E=768的情况下效果略微下降,在E=128的情况下反而有所上升。
Inter-sentence coherence loss
Bert预训练的loss使用MLM和NSP两个任务的loss,NSP即预测segment_2是否是segment_1的下一句,正样本即选取语料中的下一句,负样本的下一句则是从其他文档中选取。
Albert的论文中指出NSP的用处并不大,NSP将主题预测和连贯性预测包含在一个任务中,主题预测更简单些(来自不同文档的文本往往是不同的主题),模型会倾向于通过主题的关联去预测。并且主题预测与MLM任务学习到的知识有更高的重叠度。
Albert将NSP换成了SOP (sentence-order prediction) 任务,即预测两句话有没有被交换过顺序,使用的正样本与Bert相同,但负样本选择两个相邻的segment并交换顺序,这使得模型能够学习到主题特征以外的discourse-level更细粒度的特征。
实验结果如下,NSP任务对于SOP任务的几乎没有预测效果,52%的准确率相当于随便猜(50%的概率),但SOP在NSP、SOP、以及下游任务上的表现都明显优于NSP。

三,Bert、Roberta、Ernie和Albert对比
Bert:Bert原理及源码解读
RoBERTa (A Robustly Optimized BERT) 是 BERT 的改进版,相比于Bert,主要改进为:
- 模型规模、算力和数据上,更大的模型参数量,更大bacth size,更多的训练数据;
- 训练方法上,去掉 NSP 任务,使用动态掩码。
Ernie 百度出的Bert改进版,主要改进为:
- 对中文进行分词(不清楚在相同训练预料的情况下,分词是否真的能带来效果上的提升,个人认为,分词本身会带来误差累计,随着Transformer的能力越来越强大,分词的特征应该让Transformer当做内部特征去学习,绝大多数任务使用端到端的方式应该会更好,所以感觉中文分词是不必要存在的);
- 训练语料引入了多源数据知识。除了百科类文章建模,还对新闻资讯类、论坛对话类数据。
Albert ( A Lite Bert): Albert原理及源码解读,相比于Bert,主要改进为:
- Factorized Embedding Parameterization:词表的embedding size (E) 和transformer层的hidden size (H) 分开设置;
- Cross-layer parameter sharing,仅共享attention的参数;
- Inter-sentence coherence loss:使用MLM和SOP任务。
Albert的Factorized Embedding Parameterization主要是大幅减少模型参数量,提升预训练速度,但从效果上相比于Bert是略微变差的(base对base,large对large),但是模型规模的变小让训练Albert xxlarge更容易,所以整体效果是提升的。
(个人理解)Bert的NSP任务比Albert的SOP任务更适合两句相似度判断的场景(比如query和document的匹配程度、问答中相似问题),NSP倾向于判断两句是否有主题上的关联,SOP则学习主题以外的是否为上下句的特征。在 平安医疗科技疾病问答迁移学习比赛 中,实验结果也验证了我的想法:
| 模型 | 线上F1 |
|---|---|
| Bert | 84.58% |
| Roberta | 85.59% |
| Albert-large | 83.94% |
Albert论文的实验里也说明,有些数据集和任务上,Bert表现更优,有些Albert更优。